
Supercharging Ad Pipelines with Off-the-Shelf Cloud Tools
- Ronny Ahituv
- Dec 11, 2024
- 9 min read
In the ultra-competitive world of digital advertising, where thousands of brands compete for the best ads at the best prices, the scale of the challenge can be daunting. It requires expertise in both the visual and written aspects of ad creation, data science, and managing complex data infrastructure. However, the recent rise of advanced off-the-shelf tools from major cloud providers has transformed the landscape, enabling companies to offload much of the heavy lifting to these pre-built services. This shift allows teams to spend less time on repetitive tasks and more time focusing on what truly matters: creative innovation, cutting-edge technology, and strategic business growth.
In this blog post, we’ll explore how these new tools can serve as fundamental building blocks for creating an efficient ad pipeline. Let's get started!

1. Introduction to the World of Ads
The world of advertising wasn’t always this complex. In the past, advertisers would simply contact companies with available ad space (publishers) and negotiate prices for specific ads over a set period—a straightforward deal, reminiscent of the ‘Mad Men’ era.
Today, the landscape is vastly different. There are countless publishers and advertisers, each with unique needs and goals. Advertisers are often willing to pay more for specific spots or to reach particular audiences. To coordinate these diverse requirements, a system has evolved where auction houses pool available advertising inventory and collect bids from advertisers.
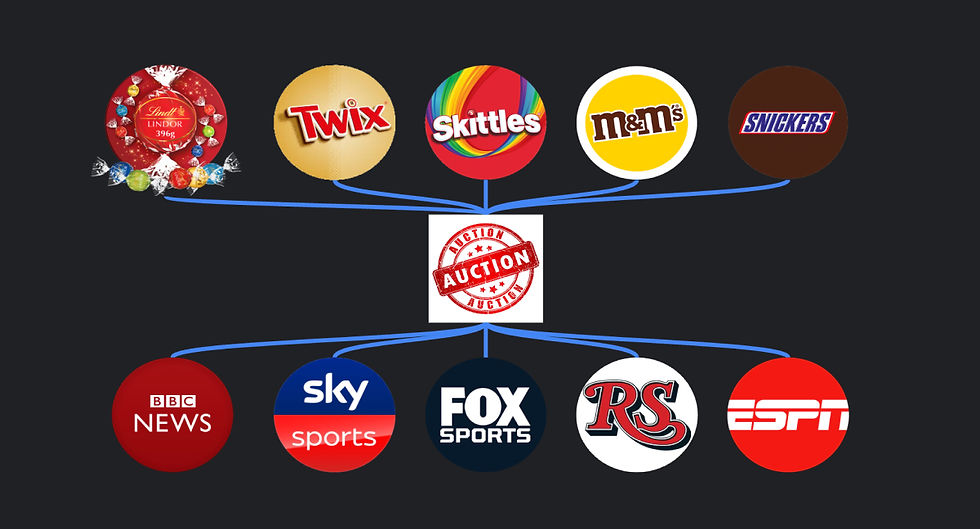
Multiple publishers (news companies in this case) and multiple advertisers (the candy companies)
The Lifecycle of an Ad
Here’s how the modern ad ecosystem typically works:
A user visits a website.
The website notifies an ad exchange (e.g., Google ADX) about the available ad placement.
The ad exchange sends a real-time bidding (RTB) request to various potential advertisers, providing details about the placement.
Advertisers or intermediaries (such as brokers) decide which content to display and how much they’re willing to bid.
The highest bidder wins the placement, and their ad is sent back to the website for display.
This process happens in milliseconds, for every ad placement across the internet.
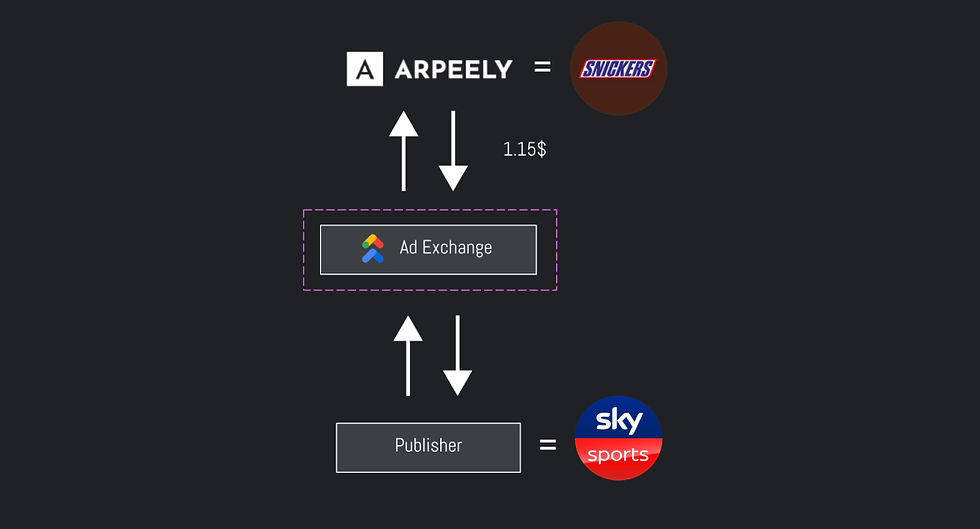
The lifecycle of an ad
The internet is massive, and systems like ours receive hundreds of thousands of potential placements every second. This generates petabytes of data and consumes enormous computational resources.
But all of this complexity and scale also creates an incredible opportunity: a treasure trove of data for machine learning.
This is where pre-built solutions provide a significant advantage. They enable us to rapidly deploy new ideas and focus on the technological components that give us a strategic edge in this hyper-competitive environment.
Further reading: The AdTech Book
2. Components of an Ad Pipeline
A successful ad pipeline consists of several key components, each designed to address a critical step in the process.

The basics of an Ad Pipeline
Content Generation: A great pipeline requires contextually relevant content. We’ll explore how Visual Question Answering (VQA) models parse context and Generative AI tools create high-quality, scalable ad content.
Value Assessment (Prediction): Accurately predicting the value of ad placements is essential for auctions. This section covers regression models, time-series models like ARIMA, and multi-modal embeddings to reduce cardinality and accelerate model training.
Exploration: To avoid stagnation, we’ll incorporate uncertainty measures and explore new content using Multi-Armed Bandit techniques like Upper Confidence Bound (UCB) and Thompson Sampling.
Monitoring and Improving: Effective pipelines rely on outlier detection for monitoring and genetic algorithms to continuously improve content and explore related domains using embeddings.
Each component is modular and can be optimized independently for a highly adaptable and efficient pipeline. Now, on to the details.
3. Using VQAs and Generative AI for Contextual Understanding and Content Creation
An ad pipeline is only as effective as the quality and relevance of its ads. To succeed, the pipeline needs a constant supply of fresh, contextually aligned ads for a variety of products and scenarios.
LLMs have revolutionized this process by enabling the rapid creation of massive amounts of content—both text and images—tailored to specific contexts. The underlying capabilities include:
VQA for Context Parsing: By passing an image (e.g., a website screenshot) to a VQA-enabled model, we can answer critical questions about the website's tone, dominant colors, or subject matter. This allows us to quickly and efficiently capture the context in which an ad will appear.

Generative AI for Content Creation: Generative AI allows us to rapidly create high-quality content, whether it’s a product-focused image, a catchy slogan, or a longer article. The outputs are fast, high-quality, and adaptable to a wide range of styles and requirements.

Putting it all together:

Creating content with LLMs
These tools are more accessible than ever, with ready made solutions from major cloud providers. Many models now support seamless integration with SQL databases and Python, making it easy to embed these capabilities directly into an ad pipeline. Moreover, we can design our pipeline to be agnostic to the specific cloud infrastructure or LLM, making it simple to swap between them.
VQA:
CREATE OR REPLACE TABLE VQA_RESPONSE AS
SELECT
*
FROM ML.GENERATE_TEXT(
MODEL MODEL_IMPORTED_FROM_GARDEN,
TABLE IMAGES_STORED_IN_CLOUD_AND_EXTERNALIZED,
STRUCT( 'What is the websites purpose (e.g., shopping, news, information)? What are the dominant colors (up to 3 colors, ordered by dominance)? Is the website design simple or busy? Answer in JSON format with 3 keys: category, color, design' AS prompt, TRUE AS flatten_json_output))Image Generation:
import io
from PIL import Image
import vertexai
from vertexai.preview.vision_models import ImageGenerationModel
vertexai.init(project=PROJECT_ID, location="us-central1")
model = ImageGenerationModel.from_pretrained("YOUR_MODEL")
generated_images = model.generate_images(
prompt=DESCRIPTION,
number_of_images=4,
aspect_ratio=RATIO).images
image_bytes = [ Image.open(io.BytesIO(img._image_bytes)) for img in generated_images ]Generic python interface
By combining these capabilities, we can quickly produce high-quality, contextually relevant ads at scale, enabling an impressive degree of personalization and innovation for any given scenario.
4. Accurate Pricing with Predictive Models
Even the best ads are ineffective if we don't accurately determine the right price to bid for ad placements. Bidding too high can result in losses despite high click rates, while bidding too low may cause us to lose auctions and prevent our ads from being displayed. It's essential to have a predictive system in our pipeline that can accurately forecast the return on investment for a given ad placement.

Predicting the value of displaying an ad
Our pipeline employs regression models that account for factors such as website context, user details (e.g. phone model), and ad specifics to predict potential returns. These models are seamlessly integrated with modern cloud databases like BigQuery and Redshift, where sophisticated predictive models can be implemented with just a few lines of code. The underlying structure remains consistent, whether you use deep neural networks, decision trees, or logistic regression, making it straightforward to introduce new ideas.
Creating a model in GCP is easy
CREATE OR REPLACE MODEL MODEL_NAME
OPTIONS(model_type='LOGISTIC_REG') AS
SELECT
feature_1,
feature_2,
target
FROM
DATABASEThe Right Pricing at the Right Time
In addition, the cyclical nature of user engagement with ads—varying significantly by time of day, weekends, and holidays—makes time-series predictions essential. In our approach, we use models like ARIMA to understand these seasonal trends, which helps us optimize our pricing strategies effectively.
CREATE OR REPLACE MODEL MODEL_NAME
OPTIONS(model_type='ARIMA_PLUS',
time_series_timestamp_col='time_hours',
time_series_data_col='rev',
horizon=24
) AS
SELECT
time_hours,
rev
from YOUR_DATABASEReducing Cardinality with Embeddings
A significant challenge in model training is the high cardinality of certain fields, such as device types, app names, and URLs. Using these high-cardinality fields directly in our models would greatly reduce their efficiency.
To address this, we harness the powerful embedding capabilities of LLMs. By employing multi-modal embedders, we can transform assets like website and app screenshots, along with their descriptions, into vectors in a high-dimensional space. These vectors can then be clustered using models like k-means or used directly as features in our predictive models.
SELECT *
FROM ML.GENERATE_EMBEDDING(
MODEL MODEL_IMPORTED_FROM_GARDEN,
TABLE IMAGES_STORED_IN_CLOUD_AND_EXTERNALIZED,
STRUCT(FLATTEN_JSON AS flatten_json_output)
)CREATE OR REPLACE MODEL MODEL_NAME
YOUR_MODEL_NAME
OPTIONS
( MODEL_TYPE='KMEANS') AS
SELECT
*
FROM EMBEDDINGS_DATABASEBy integrating these advanced predictive and embedding techniques, we ensure that our pricing is both competitive and cost-effective, maximizing the impact of our ad placements.
5. Automated Content Exploration with Multi-Armed Bandits
The world of online ads is constantly evolving, requiring the regular introduction of new content. For example, a marketing manager might suggest an ad based on a viral meme or an upcoming holiday sale.
Now, we face several questions: should we completely replace the existing ads with this new one? How long should we test the new ad before making a decision? Should we only test in certain locations or across the entire web?
These challenges are exactly what Multi-Armed Bandits (MAB), and more specifically Contextual Multi-Armed Bandits, are designed to address. We won't reinvent the wheel here, as this topic has been thoroughly covered in the literature, we will however briefly discuss how we can 'milk' the existing pipeline to achieve MAB performance with minimal additional code.
A quick win, commonly used in the industry, is achieved by implementing an Epsilon Greedy strategy, where a small percentage of traffic is allocated to randomly selected ads, while the rest is shown the best-performing ad. At Arpeely, we focus on more dynamic solutions that allow our system to explore new ad content while still capitalizing on the best-performing ads. By incorporating uncertainty estimates from our models, we ensure a balanced approach between exploring new possibilities and exploiting existing successes. This enables us to test new ads in real-time while ensuring that the most effective ads are shown to users without wasting resources.
The key advantage here is that many predictive models naturally provide some level of uncertainty. For those that don’t, we can induce uncertainty by adding noise to the data, ensuring our approach remains efficient and adaptive in optimizing ad performance.
6. Monitoring and Continuous Improvement
A crucial component of any ad pipeline is the ability to continuously monitor and improve performance. Cloud databases offer powerful tools that help ensure our system runs smoothly while also providing the insights needed to enhance the pipeline over time.
Cloud Database Tools for Monitoring
Cloud services offer us automatic access to advanced visualization and monitoring tools that help us keep track of how our ad pipeline is performing. These tools allow us to quickly identify trends, spot potential issues, and visualize key metrics. Beyond just visualizations, we also benefit from ML-based drift and anomaly detection—these cloud tools alert us when the pipeline’s performance deviates from expected patterns, helping us proactively address issues before they impact results. With these robust monitoring capabilities, we feel confident that we can track and maintain the performance of our pipeline with minimal manual intervention.
SELECT *
FROM ML.VALIDATE_DATA_DRIFT(
TABLE BASE_DATABASE,
TABLE TARGET_DATABASE,
STRUCT()
)Continuous Improvement with Genetic Algorithms
While monitoring keeps our pipeline running smoothly, genetic algorithms allow us to take the next step: continuous improvement. These algorithms enable us to iteratively enhance high-performing ads and explore new opportunities in our ecosystem.
Altering Existing Creatives: Updating ads and creating variations is easy with modern Generative AI. By applying a set of predefined adjustments—such as changes in color, tone, and style—we can generate a wide range of new ads based on existing themes. This approach allows us to continuously refine our creatives without starting from scratch, ensuring our ads stay fresh and aligned with the latest trends.
Exploring Around Lucrative Sites: Thanks to the embedding vectors from Part 4, which capture the latent similarities between various contexts (URLs, domains, ads), exploring successful ad placements is greatly enhanced. By identifying “neighbors” in the high-dimensional embedding space, we can quickly pinpoint similar sites or domains that may also be valuable for ad placement. This capability allows us to continuously discover and test new locations for our ads, leveraging the rich context already captured by our system.
Together, these two components—cloud-based monitoring tools and genetic algorithms—enable us to keep improving our ad pipeline. Whether we're refining creatives or expanding our reach, we’re equipped to adapt and grow in a highly dynamic environment.
7. Harnessing the Power of Off-the-Shelf Cloud Tools
As we’ve seen throughout this post, a successful ad pipeline consists of several interconnected components that work together to optimize performance. Here's a quick recap of what we've covered:
Content Generation: Using Visual Question Answering (VQA) models to parse context and Generative AI tools to create high-quality, scalable ad content.
Value Assessment (Prediction): By leveraging regression models, time-series models like ARIMA, and multi-modal embeddings to address the high cardinality in our environment, we can accurately predict ad placement values.
Exploration: Utilizing uncertainty measures and Multi-Armed Bandit techniques to test new ad content and prevent stagnation.
Monitoring and Improving: Relying on outlier detection for monitoring and genetic algorithms for iteratively enhancing content and discovering new domains for ad placement.
Key Advantages of Off-the-Shelf Cloud Tools
By leveraging these solutions, we gain several important advantages:
Rapid Deployment: With pre-built components, we can launch and test new ideas in days, rather than months. This enables quick adaptation to new opportunities and faster iteration.
Proven Reliability: Cloud services are built to scale, ensuring performance even under a heavy load. These solutions have been rigorously tested, so we can rely on them as our pipeline grows.
Modular Design: The modular nature of cloud tools means each part of the pipeline operates independently. This provides clarity, better management, and optimized areas of the system, allowing for informed decision-making and troubleshooting.
Focusing on Core Competencies
Utilizing cloud tools allows our team to focus on what matters most: innovation, strategy, and execution. By offloading routine tasks to these solutions, we free up time and energy to drive impactful business results. This empowers us to push the boundaries of creativity and technology, ultimately making a meaningful difference.
Thanks for reading. These new technologies are truly incredible, and the possibilities they unlock are just beginning.



Comments